
(java의) 객체 지향 언어와 (db의) sql 언어의 패러다임의 불일치 때문에 JDBC에서 JPA를 주로 쓰는 위주로 바뀐다.
"jdbc의 특징에는 sql문이 주로 들어가고, connecton 관리, preparedstatement, resultset 객체가 있다."
1. connection 객체가 db와 app의 연결을 관리하고
2. preparedstatement가 sql을 전달하고
3. resultset객체를 통해 결과값을 전달한다.
:buffer를 통해서 결과값을 가져온다.
jdbc api로 db와 java application사이에서 가져오는 것인데
jpa api는 java applicaion과 jdbc api 사이보다 더 db를 사용하지 않는것
ORM의 장점
sql문을 직접 적을 경우가 적어진다.
sql 구조를 java application 내에서 적용하지 않아도 된다.
awful?(단점)
jpa-hibernate awful 구글에 쳐보기
JDBC - SQLMAPPING- ORM
persistence ( 영속성 ) : 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성
영구히 저장되는 그 어떤 것을 영속성, DB에 저장해야 객체가 영속성을 가진다.
- 상태를 유지하기 위해
- 데이터가 사용후에도 유지되기 위해(*영속적이어야 한다)
- 데이터가 저장되고 읽고 업뎃하고 수정되고 삭제되기 위해 등
그림으로 이해하자면 밑에 이미지 형식으로 이해하면 될 듯 하다.


Persistence Framework를 이용하는 방법은 SQL Mapper , ORM 으로 나뉜다.
영속성을 어떻게 부여할 것인가. : JDBC, SQL MAPPER, ORM
가장 효율적으로 기술을 배우는 방법
어떤 분의 생각으로 역사, 쓰임, 배경 을 배워야 task를 해결할 수 있다고 한다.
사용툴
- JDBC : JDBC API
- SQL MAPPER : MyBatis,Spring JDBC
- ORM : JPA, Hibernate, Spring Data JDBC/JPA
Spring Data JDBC가 ORM 이 아니라는 얘기가 있다.
DB Connector에 대한 니즈가 증가함
Driver에 따라 Manager를 다르게 했다.
1. DriverManager를 이용해 Connection인스턴스를 얻고
2. Connection을 통해서 Statement를 얻는다.
3. Statement를 이용해 ResultSet을 얻는다.

MyBatis ; SQL을 분리하자, Query를 Java에서 XML로 바꾸기

MyBatis
Application이 중요
method에 query를 매핑해서 xml을 관리
sqlSession을 오픈해서 mapper를 변경하고
ORM(Object-Relational Mapping)
객체지향(추상화, 정보은닉, 상속)을 사용하는 것이 객체지향언어의 패러다임인데,
sql에 의존적인 개발하는 것이 옳은가? 해서 보완하기 위해 만들어내기
물리적으로 sql과 jdbc api를 데이터 접근 계층에 숨기는데 성공했을지 몰라도,논리적으로 엔티티와 강한 의존 관계를 가지고 있다 : 패러다임의 불일치가 일어난다. : 객체 지향을 안하게 하는 것을 보완하기 위해 ORM을 사용한다.
JPA 표준 인터페이스 : Hibernate, EclipseLink, DataNucleus

핵심모델 : ENTITY MANAGER 와 영속성 컨텍스트

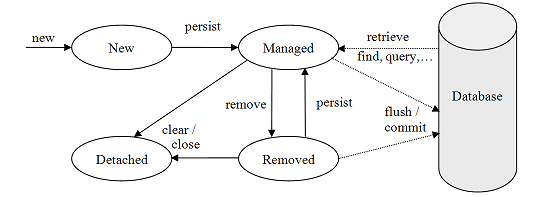
- LAZY LOADING : 필요한것만 가져오기(??)
- DIRTY CHECKING : 엔티티 매니저가 어디가 바뀌었는지 확인하는 것
- CACHING : 캐시를 도와주는 것(??)
Spring Data JDBC : Domain Driven Design 기반
"Spring Data JDBC a simple, limited, opinionated orm"

- No Lazy loading
- No Session(Caching)
- No Proxies
- No Flushing : save와 동시에 query(쓰기 지연 저장소 없음)
- No Many to x Relation

나의 이해도
이해는 개념적으로 약간 숙지가 된듯하다. 김영한님의 설명이 확 머리에 박혀서 패러다임의 불일치와 객체지향언어의 특징들이 계속 머리에서 멤돌거나 떠돌아 다닌다. 조금더 코드를 작성해서 확인하는 방법을 해봐야 명확히 알 것 같다.
나는 코드를 좀 덜치는 습관이 있는데*이론으로 맥락이해가 안되면 코드 복사밖에 못하는 스탈..* 이걸 고치기 위해 이론 먼저 조금 숙지 후 코드치기 연습을 하려한다. 실습위주로 하는 것도 좋긴한데 뭐부터 잡아야 할지 모르겠어서 헤멘다.
그런 애로사항을 고치기 위해 실습강의, 책위주로 학습하고 이론은 여기저기서 모아서 맥락 이해를 잡으면서 실습을 해간다.
요즘들어 깊게 이해해보고 정확히 나만의 언어로 표현할 수 있게끔 연습해보고 있다. 화이팅하자!
REFERENCE
- 우테, 테크톡:JPA와 JDBC
- 우테. 테크톡 : JDBC, SQL MAPPER, ORM
- 우테. 테크톡: ORM vs SQL Mapper vs JDBC
- https://medium.com/@dilshanramesh81/data-persistence-add16cb74cf3
- https://isd-soft.com/tech_blog/behold-almighty-orm/
- Persistance Context
- 자세하게 적어놓은 블로그
- ENTITY MANAGER 예시
- Spring Data JDBC
- 공식 reference : Spring Data JPA : 2.7.2
- 공식 reference : Spring Data JDBC 2.4.2
'ORM > JPA' 카테고리의 다른 글
| [JPA / Querydsl, JPQL] 복잡한 쿼리와 동적 쿼리 처리를 위한 querydsl, JPQL 소개 (0) | 2022.08.22 |
|---|
